Introduction
This short article describes an extension of the Longest Common Sub-string (LCS) problem with maximal consecutive. Personally I used this algorithm in computing the gloss overlaps (Lesk algorithm) for finding the number of shared common words between two strings (it means gloss here).
Some applications of the LCS problem include:
- Searching for proteins with similar DNA sequences: DNA sequences (genes) can be represented as sequences of four letters ACGT, corresponding to the four submolecules forming DNA. When biologists find a new sequence, they typically want to know what other sequences it is most similar to. One way of computing how similar two sequences are is to find the length of their longest common subsequence.
- Approximate string matching like spell checkers.
- File comparison (used in diff, CVS, source comparer, cheater finder, plagiarism detection).
Preparing the ground
The original LCS problem
Let us start with a simple approach, given are two strings: short string (sentence) and long string (text), as in the string matching problem. You want to know if all the words of the sentence appear in order (but possibly separated) in the text. If they do, we say that the sentence is a subsequence of the text. That is the "longest common" is the subsequence of "the longest shared common between two strings". If they do not occur in the text, it still makes sense to find the longest subsequence that occurs both in the sentence and in the text. This is the longest common subsequence problem:
- Given two strings/sequences X and Y. Each string is composed by a list of words or abbreviations. We denote m to be the length of X and n to be the length of Y.
- Z is called as common subsequence, if it is subsequence of both X and Y.
- The requirement is finding the common subsequence which has the maximum length among all the possible common subsequences of X and Y.
Basic solution
How would we solve this problem? Can we find the overlapping sub-problems such that the optimal solution to the LCS problem consists of optimal solutions to the sub-problems?
Dynamic programming gives us a way of making the solution more efficient but the idea does not tell us how to find this:
- Think of "optimal substructure'' property (break into optimal subproblems).
- Think of a recursive solution.
There are two ways to implement dynamic programming: first is top-down (memoization) and second is bottom-up. The top down method is closer to the original recursive algorithm, the bottom up method is usually a little more efficient.
Optimal substructure
Let 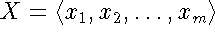 and
and  be sequences (xi is from prefix to i), and let be any LCS of X and Y.
be sequences (xi is from prefix to i), and let be any LCS of X and Y.
- If , then and are LCS of and .
- If , then implies that Z is an LCS of and Y.
- If , then implies that Z is an LCS of X and .
Recursive Formulation
The major idea of the dynamic programming solution is to check whenever we want to solve a sub-problem, whether we've already done it before. Each time we need the solution to a sub-problem, we first look up if that one's already in the array table, and return right away if it is. Otherwise we will perform the computation and store the result.
We define an array to store the sub-problem results of the previous step: C[i, j] = k to be the length of the LCS of X[1.. i] and Y[1.. j], where 1 <= i <= m and 1 <= j <= n.
Question is: Would the optimal solution for C[i, j] consist of optimal solutions for C[i', j'], where i' <= i and j' <= j?
There is one thing we have to worry about, and that is when we fill in a cell C[i, j], we need to already know the values it depends on, which in this case are C[i-1, j-1], C[i , j-1], and C[i-1, j]. Due to this reason we'll traverse the array forwards, from the first row working up to the last and from the first column working up to the last.
Bottom-up vs. Top-down (Recursive + Memorization)
The recursive algorithm gives us an order of filling the results in (going recursively from bigger to smaller), and this is known as memorization. One disadvantage of memorizing is that this fills in the entire array even when it might be possible to solve the problem by looking at only a fraction of the array's cells. In other words, we can also get the same results by filling them in another order.
There is one fact here, that iteration is usually faster than recursion. So we use a simpler way by applying iteration instead of recursion, that visits the array systematically. This order will fill in the array from smaller simpler sub-problems to bigger more complicated ones, this is also called as bottom up.
Pseudo-code shows bottom-up dynamic programming:
LCS-Delta(X,Y)
m <- LENGTH[X];
n <- LENGTH[Y];
for i <- 1 to m, do c[i,0] <-0;
for j <- 0 to n, do c[0,j] <-0;
back <- c;
for i <- 1 to m, do {
for j <- 1 to n do {
if (x[i] = y[j]) {
c[i,j] <- c[i-1, j-1]+1;
back[i,j] <- "UP&LEFT";
}
else if (c[i-1,j] >= c[i,j-1]) {
c[i,j] <- c[i-1,j];
back[i,j] <- "UP";
}
else
c[i,j] <- c[i,j-1];
back[i,j] <- "LEFT";
}
}
return c and back
Getting the subsequence itself
Sometimes you may need the subsequence itself, not just its length. Once we have filled in the arrays C and back described above, we can find the sequence by working backwards through the backtracking array.
Pseudo-code shows trace back:
int i<-m, j <- n,
score <- c[m,n];
string lcs=empty;
while (i >0 || j>0)
{
if (back[i, j] = "UP&LEFT")
{
i--;
j--;
lcs=X[i] + lcs;
}
else if( back[i,j] = UP )
i--;
else if ( back[i,j] = LEFT )
j--;
}
return score and lcs;
Extending LCS with maximal consecutive
I used LCS to deal with the problem of measuring the overlaps between two strings. A problem I have faced is that the basic LCS just concerns on the length of the common subsequence. I not only need the longest common subsequence but also the one which consists of the maximal consecutive subsequences. One motivated reason is that a three common shared consecutive words overlap is more significant than three one separate or different order words. It is based on ZipF's Law, which says that the length of words is inversely proportional to their usage. There is a fact that a phrase N-consecutive word is less occurring than a N-non-consecutive (or single) word. In other words, the shortest words are those which are used more, the longest ones are used less.
Take an example: given a target sequence/sentence X, and two sequence candidates Y and Z to select to be matched with X:
X: "A B C D E F G H"
Y: "A B C D U V Y K"
Z: "A I B T C O D L"
The basic LCS gives us the same result in both cases (X and Y, X and Z): LCS is "A B C D" and score is the LCS length of 4. It does not differentiate the consecutive relation of their sequence. In this case, Y should be ranked as a better candidate than Z because it has shared a more consecutive sequence with X.
In another example, given two sequences and we want to know the maximal consecutive LCS of them (2):
X="AA BB CC BB II CC KK DD H I K"
Y="AA BB CC DD E F G"
=> there are two possible LCS have the same length:
Case <SUB>1</SUB>. X="AA BB CC BB II CC KK DD H I K" and
Y="AA BB CC DD E F G"
Case <SUB>2</SUB>. X="<FONT color=#0000ff>AA</FONT> <FONT color=#000000>BB CC</FONT> <FONT color=#0000ff>BB</FONT> II <FONT color=#0000ff>CC</FONT> <FONT color=#000000>KK</FONT><FONT color=#0000ff> DD</FONT> H I K" and
Y="<FONT color=#0000ff>AA BB CC DD</FONT> E F G"
=> the case <SUB>1 </SUB>should be a better result than case <SUB>2</SUB>.
This makes sense to find a new scoring mechanism to assign different scores to consecutive sequences.
New scoring mechanism
The scoring mechanism is required to differentiate between N-single ordered separate words and N-consecutive words. In other words, consecutive words are scored higher than non-consecutive words.
The scoring function f must satisfy f(x+y) > f(x) + f(y) for any positive integer x and y. In other words, the score of N-consecutive words should be greater than the sum of N-separate words. To avoid the complexity in finding out the f(k) form, we can easily observe that there is a possible function family in the polynomial family of the form ka where a>1. We can observe that (a+b+c...)2 > a2 + b2 + ... , so I chose f(k)=k2 in this work. Therefore, the LCS in Case 1 is ranked with a higher score than Case 2, so it will return Case 1 as the best result in the example (2) with a score of 10 (=32 + 11).
This pseudo-code shows an adapted LCS with maximal consecutive:
int CScore(int length)
{
return length*length;
}
Adapted algorithm:
LCS-Delta(X,Y)
m <- LENGTH[X];
n <- LENGTH[Y];
for i <- 1 to m, do c[i,0] <-0;
for j <- 0 to n, do c[0,j] <-0;
back <- c;
mc <- c;
for i <- 1 to m, do {
for j <- 1 to n do {
if (x[i] = y[j]) {
k <- mc[i-1,j-1];
delta <- CScore(k+1) - CScore(k);
c[i,j] <- c[i-1, j-1] + delta;
back[i,j] <- "UP&LEFT";
mc[i,j] <- k + 1;
}
else if (c[i-1,j] >= c[i,j-1]) {
c[i,j] <- c[i-1,j];
mc[i,j]<- 0;
back[i,j] <- "UP";
}
else
{
mc[i,j] <- 0;
c[i,j] <- c[i,j-1];
back[i,j] <- "LEFT";
}
}
return c and back
Using the code
The code is also short like the article itself. Each string will first be tokenized into a list of words, this phase will also remove some stop words which are frequently occurring (insignificant words).
Each word will then be stemmed; stemming is the process of finding out the base form of a word, i.e.: collecting -> collect. The Porter Stemmer (FST - Martin Porter) algorithm is used to treat this work. The Porter Stemmer algorithm is a process for removing the commoner morphological and inflexional endings from words in English. One restriction is that after stemming a word, I do not use a dictionary to check the existance of the base forms. This work will be done by using the WordNet.Net.
This is an example of using the code:
string s1="hello codeproject are you ok ?";
string s2="hello codeproject how are you today?";
string lcs=LCSFinder.GetLCS(s1, s2);
The result of this example is : "hello codeproject you" (the word "are" is ignored because it is a stop word).
Point of interest
This article could be a good entry for a beginner to start learning dynamic programming - a very nice programming methodology.
Conclusion
The pseudo-code samples are just intended for illustration. Thanks to M.A. Warin for his helps.
- 09/07/2005: Simplifying the article.
- 09/10/2005: Added something about maximal consecutive.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









 i've refactored the LCS function as following:
i've refactored the LCS function as following: